查询
全量查询
使用match_all
{
"query": {
"match_all": {}
}
}
单字段匹配查询
使用match,同时支持精确搜索与全文搜索,全文搜索时,搜索词分词,对应字段的内容存在一个词条匹配即可
{
"query": {
"match": {
"genre": "科幻"
}
}
}
多字段匹配查询
使用multi_match,至少一个字段存在一个词条匹配即可
{
"query": {
"multi_match": {
"query": "美国",
"fields": ["chinese_name", "area"]
}
}
}
使用正则表达式,查询所有字段
{
"query": {
"multi_match": {
"query": "美国",
"fields": ["*"]
}
}
}
组合查询
must数组中的条件之间为与关系must_not数组中的条件之间为与非关系should数组中的条件之间为或关系must、must_not、should数组之间是与关系
使用should时,假如没有使用平级的must和filter,则至少需要满足should数组中的一个条件,否则默认情况下可以不满足should数组的条件。这时可以通过minimum_should_match限制至少需要满足should数组中的条件个数
{
"query": {
"bool": {
"must": [
{"match": {"area": "美国"}},
{"match": {"genre": "科幻"}}
],
"must_not": [
{"match": {"language": "日语"}}
],
"should": [
{"match": {"name": "man"}},
{"match": {"name": "woman"}}
],
"minimum_should_match": 1
}
}
}
嵌套组合查询
{
"query": {
"bool": {
"must": [
{"match": {"area": "美国"}},
{"match": {"genre": "科幻"}},
{"bool": {
"should":[
{"match": {"name": "man"}},
{"match": {"name": "woman"}}
]
}}
]
}
}
}
模糊查询
可修正拼写错误,使用fuzziness指定编辑距离
{
"query": {
"match": {
"name": {
"query": "iran",
"fuzziness": "AUTO"
}
}
}
}
通配符查询
使用wildcard
?匹配一个任意字符*匹配零个或多个字符
{
"query": {
"wildcard": {
"chinese_name": "*侠"
}
}
}
正则表达式查询
使用regexp,对text类型的数据,正则表达式匹配的是分词后的词条
{
"query": {
"regexp": {
"name": "i.{3}"
}
}
}
短语匹配查询
使用match_phrase,对搜索词分词,搜索词的所有词条都要匹配对应字段值的词条,且词条需要相连
{
"query": {
"match_phrase": {
"chinese_name": "不能说的"
}
}
}
通过slop设置词条之间的最大间隔,默认为0,即词条需要相连
{
"query": {
"match_phrase": {
"chinese_name": {
"query": "不能说秘密",
"slop": 1
}
}
}
}
短语前缀匹配查询
使用match_phrase_prefix,在短语匹配的基础上,最后一个词条支持前缀匹配,使用max_expansions控制最多匹配结果数
{
"query": {
"match_phrase_prefix": {
"chinese_name": {
"query": "不能说秘",
"slop": 1,
"max_expansions": 5
}
}
}
}
词条查询
使用term,支持精确搜索和全文搜索,搜索词不分词
{
"query": {
"term": {
"id": 5
}
}
}
范围查询
使用range
{
"query": {
"range": {
"id": {
"gte": 10,
"lt": 1000
}
}
}
}
过滤查询
使用filter,过滤查询部分先执行,结果会被缓存,且不参与评分
{
"query": {
"bool": {
"must": [
{"match": {"genre": "科幻"}}
],
"filter": {
"range": {
"id": {
"gte": 5,
"lt": 1000
}
}
}
}
}
}
配合constant_score使用,跳过评分
{
"query": {
"constant_score": {
"filter": {
"term": {
"id": 5
}
}
}
}
}
搜索结果处理
搜索结果去重
使用collapse,注意去重字段不能是text类型
{
"query": {
"constant_score": {
"filter": {
"term": {
"id": 5
}
}
}
},
"collapse": {
"field": "id"
}
}
指定数据列
使用_source
{
"query": {
"constant_score": {
"filter": {
"term": {
"id": 5
}
}
}
},
"_source": ["id", "name"]
}
分页
使用from和size
{
"query": {
"constant_score": {
"filter": {
"term": {
"id": 5
}
}
}
},
"from": 0,
"size": 5
}
排序
使用sort
{
"query": {
"multi_match": {
"query": "美国",
"fields": ["*"]
}
},
"sort": [
{"id": {"order": "asc"}},
{"celebrity_id": {"order": "desc"}}
]
}
搜索评分调整
提高字段匹配的评分
在设置字段时,在字段末尾加上^
{
"query": {
"multi_match": {
"query": "美国",
"fields": ["chinese_name^2", "area"]
}
}
}
提高语句匹配的评分
使用boost
{
"query": {
"bool": {
"should": [
{"match": {"name": {"query": "man", "boost":"2"}}},
{"match": {"name": "woman"}}
]
}
}
}
字段值因子
使用function_score和field_value_factor,可通过modifier控制因子的变换,默认为none,即对因子不做变换。提高评分的方式可通过boost_mode设置,默认为直接将原评分乘以因子值
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "美国",
"fields": ["*"]
}
},
"field_value_factor": {
"field": "rating",
"modifier": "none"
},
"boost_mode": "multiply"
}
}
}
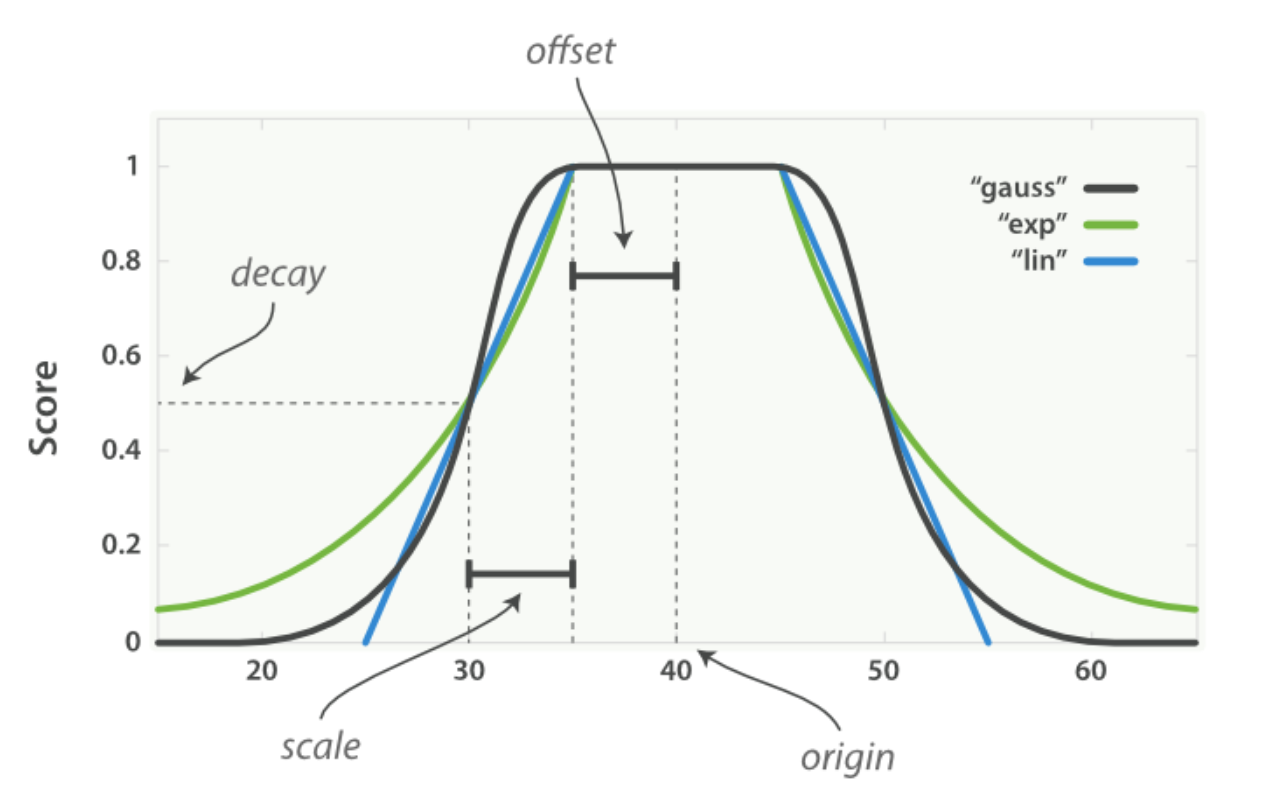
衰减函数
使用function_score和functions,越距离字段指定的中心值,评分越高
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "美国",
"fields": ["*"]
}
},
"functions": [
{
"exp": {
"year": {
"origin": 2008,
"offset": 1,
"scale": 20
}
}
},
{
"linear": {
"rating": {
"origin": 8.5,
"offset": 0,
"scale": 2
}
},
"weight": 2
}
],
"boost_mode": "replace"
}
}
}
衰减函数参数示意图
搜索聚合
去重计数
使用cardinality,非精确计数,可通过precision_threshold设置计算在多少数量之内保证精确
{
"aggs": {
"id_count": {
"cardinality": {
"field": "id",
"precision_threshold": 100
}
}
}
}
计数
使用value_count
{
"aggs": {
"id_count": {
"value_count": {
"field": "id"
}
}
}
}
平均值
使用avg
{
"aggs": {
"rating_avg": {
"avg": {
"field": "rating"
}
}
}
}
求和
使用sum
{
"aggs": {
"rating_sum": {
"sum": {
"field": "rating"
}
}
}
}
最大值
使用max
{
"aggs": {
"rating_max": {
"max": {
"field": "rating"
}
}
}
}
最小值
使用min
{
"aggs": {
"rating_min": {
"min": {
"field": "rating"
}
}
}
}
字段值分组
使用terms
{
"aggs": {
"id_term": {
"terms": {
"field": "id"
}
}
}
}
数值间隔分组
使用histogram
{
"aggs": {
"rating_histogram": {
"histogram": {
"field": "rating",
"interval": "1"
}
}
}
}
日期间隔分组
使用date_histogram
{
"aggs": {
"update_date_histogram": {
"date_histogram": {
"field": "update",
"calendar_interval": "day",
"format": "yyyy-MM-dd"
}
}
}
}
数值范围分组
使用range,from边界值不包含,to边界值包含
{
"aggs": {
"rating_range": {
"range": {
"field": "rating",
"ranges": [
{"key": "low", "to": "6.0"},
{"key": "medium", "from": "6.0", "to": "8.0"},
{"key": "high", "from": "8.0"}
]
}
}
}
}
分组后指定聚合
{
"aggs": {
"rating_histogram": {
"histogram": {
"field": "rating",
"interval": "1"
},
"aggs": {
"id_count": {
"value_count": {
"field": "id"
}
}
}
}
}
}