概念
内存重排序(Memory Reordering)是指,程序执行时与内存交互的顺序与程序源码中的编写顺序不一致
为了便于理解,此处我们将高速缓存看作是内存的延申,先把高速缓存与内存看成是一个整体,并以内存一词并称
例如,在某一程序源码中,有两个写操作A和B,且代码的编写顺序是先执行写操作A,后执行写操作B。但程序实际执行时,与内存的交互却是操作B先于操作A。也就是说,对于其它观测者(另一线程、或另一CPU内核)而言,写操作B先于写操作A
又如,在某一程序源码中,有两个读操作A和B,且代码的编写顺序是先执行读操作A,后执行读操作B。按此执行顺序,读操作B应该从内存中读取到与读操作A同样新或更新的数据,但程序实际执行结果可能相反,读操作A从内存中读取到更新的数据。这样的结果看起来是先执行读操作B,后执行读操作A
出现原因
造成内存重排序的主要原因有以下几点
- 编译期指令重排序,编译器可根据自己对代码的分析,在编译期对指令进行重排序,以优化性能
- 运行时指令重排序,例如CPU在执行指令时,可让数据已准备好的指令先执行,以优化性能
- 高速缓存性能优化带来的内存重排序
由此可见内存重排序实际为性能优化的副产物
影响
编译期与运行时指令重排序的唯一原则是,不改变程序单线程下执行的表现。而高速缓存带来的内存重排序问题,也是基于多核多线程的执行环境。所以在单线程的环境下,内存重排序甚至无法被观测到。
而在多线程环境下,尤其是lock-free程序,内存重排序会带来可见性问题,程序的执行会产生非预期的结果,也就是会导致线程不安全
解决
根据内存重排序问题的出现原因,可以给出对应的解决方法
- 单纯编译期指令重排序导致的内存重排序,也称编译器重排序,这种情况多见于单核环境。可以通过加入编译器屏障,指示编译器在某些关键位置不要重排指令。通常,程序调用一个外部函数,会隐式地加入编译器屏障
- 运行时产生的内存重排序,包括运行时指令重排序,高速缓存性能优化带来的内存重排序,也统称处理器重排序,可以通过加入CPU屏障指令(fence instructions)解决,CPU屏障指令通常表现为内存屏障。加入CPU屏障指令同时也意味着在编译期加入编译器屏障(由编译器厂商实现),会连带解决编译期指令重排序导致的内存重排序
内存模型
不同的硬件设备,会实现不同的硬件内存模型。硬件内存模型可以告诉我们,对于某段汇编代码(或机器代码),会预期出现什么类型的内存重排序。越强的硬件内存模型,在不采取任何措施(例如加入内存屏障)的情况下,预期出现的内存重排序的种类越少
与硬件内存模型对应的,还有软件内存模型的概念。软件内存模型一般是由具体的编程语言定义,隐藏了硬件内存模型的细节。软件内存模式可以告诉我们,对于某段该语言的代码,会预期出现什么类型的内存重排序。一般在应用开发的时候,我们会更多地关注软件内存模型
假如内存读取指令已经隐式包含acquire语义,同时内存写入指令已经隐式包含release语义,则称这样的内存模型为强内存模型,否则称为弱内存模型。x86/64架构属于典型的强内存模型
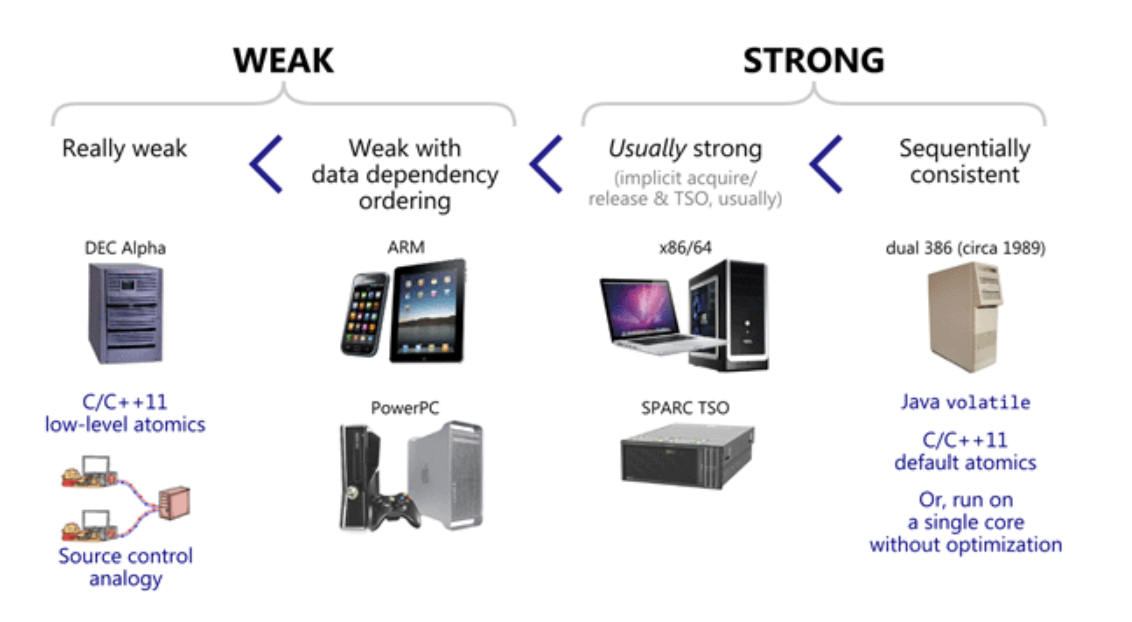
前文的讨论都是以最弱的内存模型为前提,即预期会出现所有类型的内存重排序
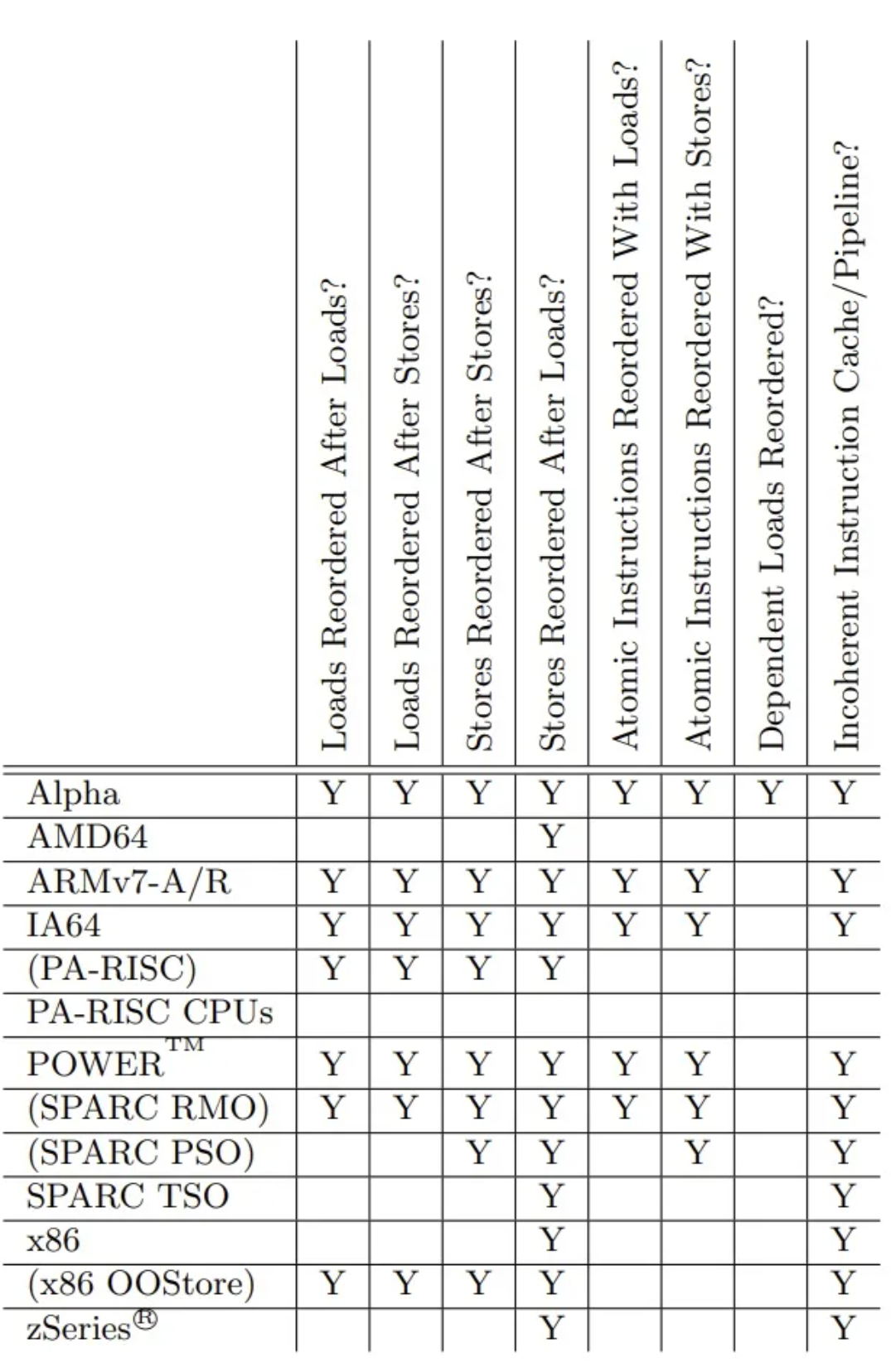
下图为不同CPU架构实现的硬件内存模型,预期会出现的内存重排序种类